This is a transcript of a talk given at the CHR2022 conference. For the corresponding paper, see https://ceur-ws.org/Vol-3290/short_paper2780.pdf.
Lexical diversity
One of the simplest and most basic corpus statistics is the number of unique words in a text. This number gives us a quick and straightforward picture of the lexical diversity of a text. Lexical diversity is typically implemented by measuring the number of unique letter combinations. This is of course very easy to do, but it doesn’t necessarily describe the lexical richness of a text adequately. This becomes clear when we compare the following few sets of words:
- cat, progesterone, remember, blue
- cat, dog, blue, red
- cat, dog, bird, rabbit neighbors
- naighbors, neigbors, neighbours
If we define a unique word as a unique orthographic combination of letters, then all these sets have a lexical diversity of 4. That doesn’t seem to match our intuition. The first set seems much more diverse semantically than the third set, let alone the last set with only historical spelling variants of the same word.
Ecological diversity
In our paper, we investigate the application of a new measure of lexical diversity, which takes the semantic differences between words into account. This measure is called “Functional Diversity”, which we borrow from the field of ecology where a similar problem exists (also see Undetected Functional Attribute Diversity). Compare for example these two ponds. In both ponds, we find 4 unique animal species. As such, we could conclude that the biodiversity is the same in both ponds. But intuitively, that categorical measure of diversity doesn’t seem right: the pond on the right looks much more diverse than the pond on the left. Functional diversity recognizes this intuition by including the similarities and differences in species’ traits.

Functional diversity
The specific implementation of functional diversity that we apply was originally developed by the biostatistician Anne Chao and her colleagues (Chao et al. 2019; Chiu and Chao 2014). In this framework, we group together all word types with a distance less than a certain threshold. (Let’s call that threshold \(\tau\) for convenience.) For example, take the words apple and pear, which are represented here as circles. The size represents how many tokens we have of each word. The distance between these two words is measured to be 0.4. If we set the threshold \(\tau\) to a value that is equal or smaller than this 0.4, then each word type forms its own functional group. So, one group for apple, and one for pear – which yields a total functional diversity of 2.
Beyond this first level, where \(\tau\) is set to the minimal distance, we start allowing words to form groups. For example, if we set the distance threshold to 0.6, apple and pear are merged together. Yet, they don’t form a single functional group, because they only overlap partially, and not completely: in the framework we employ, each type can contribute to one or more functional groups in a way that is proportional to their frequency. To know the size of a functional group, then, we take all tokens of a word type, for instance pear, plus a fraction of the tokens of any other word type, like apple, that is functionally indistinctive of pear.
The higher the threshold for \(\tau\), the more word types are merged into functional groups. Here we add the word computer, which has a distance of 0.8 to apple and 1 pear. With \(\tau\) set to 0.6, computer still forms its own functional group, but with a value of 0.8 or higher, it is partially merged with apple. Note that this also updates the composition of the apple functional group.
We can continue increasing the threshold value, until eventually all words will belong to the same functional group. In other words, this method enables us to not just talk about diversity at one level, but at a continuum of levels.
Representation of words and their distances
The computation of functional diversity requires a way of measuring similarity between words and specifically we focus on lexical semantics. Traditional lexicon-based methods like WordNet are discouraged whenever the goal is to compute the similarity in an open-set scenario, where full coverage would be hard to obtain. A second option is to compute similarities in a word embedding space such as the one obtained through an algorithm like word2vec. The problem we faced here is that the quality of embeddings for infrequent words is poor, considering that the corresponding vectors have been updated very sparsely during training. For this study, we focused on contextualized word embeddings extracted from a Large Language Model like BERT. The intuition is that even in the case of low frequent words (including, for example, misspelled words) a model like BERT can still rely on the sentential context in order to infer the semantics of a word. In terms of models, we relied on MacBERTh, which is a historical language model for English following the architecture and parameterization of BERT base uncased (Manjavacas and Fonteyn 2022).
Results
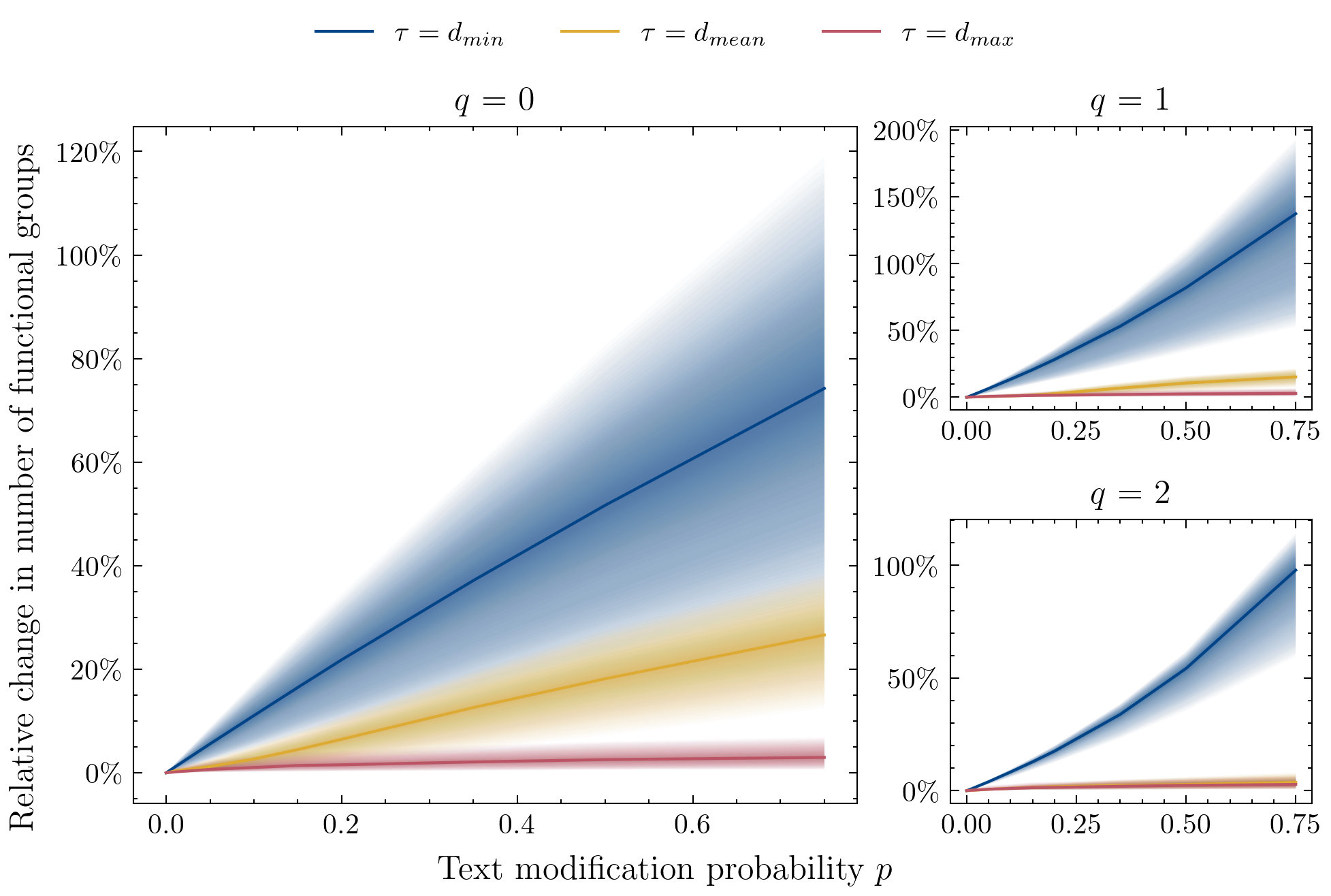
Functional diversity is affected less by increased orthographic variation
Our analyses and results led to two important insights. First, we found that diversity at the level of functional groups is affected less by non-meaningful variation such as OCR errors and orthographic variation, which are very common in historical corpora. To learn more about these results, we refer to Section 4.1 in the paper.
Functional diversity is a theoretically relevant complement to lexical diversity
We also found that approaching the ‘vocabulary richness’ of a text through the lens of the attribute diversity framework allowed us to identify text pairs that had approximately the same number of unique word types, but a diverging number of functional groups. This indicates that, while the size of the texts’ vocabularies may be the same, one text covers a broader semantic range with its vocabulary. A nice example to illustrate this is the pairing of this fiction text with an advertisement, where the advertisement has fewer functional groups at \(d_\textrm{mean}\) than the fiction text.
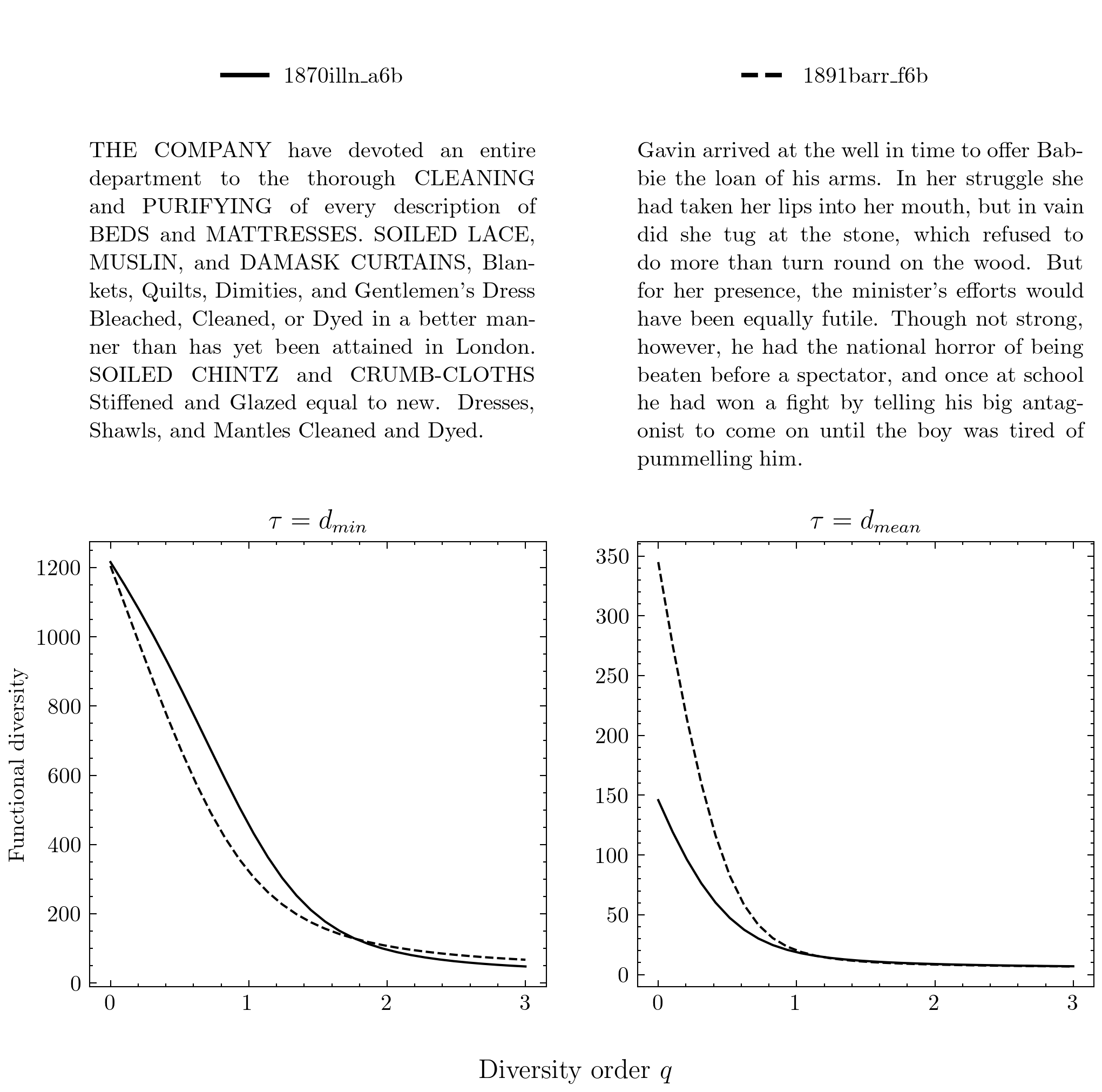
So why is that the case? Well, because advertisements often present a list of closely related services and/or goods, and hence, while they may use a large number of unique words, they cover less functional-semantic ground than for instance fiction texts.
Future work
Of course, this short paper was just an exploration of an idea, and more work has to be done. In fact, there are a few directions in which all this could go. First, We worked with MacBERTh, but there are other ways of implementing functional similarity. For instance, MacBERTh produces token embeddings, so to obtain a single representation per unique string of characters we work with an averaged representation. This may not be ideal, and perhaps there are other ways to approach this – which is something we are looking into.
But also beyond the technical side of things, we see concrete case studies to apply this method to. Naturally, this can be applied to studies in stylistics. Does, for instance, an author’s vocabulary become more diverse as they age? And if so, does it become more evenly spread across more semantic fields, or does it rather just become more detailed within the same number of fields? Or can we characterize literature for children or second language learners, which is often defined at different reading levels, in terms of categorical as well as functional lexical diversity?